Thank you for considering reading this blog post to gain knowledge on How to Check for Duplicate Content.
In the dynamic world of digital presence, where every click, keyword, and pixel counts, the expression “content is king” has become more than a catchphrase—it’s a guiding concept for online success.
However, during the drive for originality and relevance, there is a subtle threat: duplicate content.
The hidden shadow can damage your SEO efforts, dilute your brand messaging, and even result in search engine penalties.
But don’t worry—in this comprehensive tutorial, we’ll explore the dark corners of duplicate content.
From comprehending its complexities to mastering the art of detection and prevention, join us as we unveil the mysteries of duplicate content and pave the path for a brighter, more optimized digital future.
Welcome to a world where knowledge reigns supreme, and spotting duplicate content is the key to achieving SEO success.
Table of Contents
ToggleHow is Duplicate Content Defined?
For every website owner or SEO enthusiast, knowing what duplicate content is in the broad world of digital content is essential.
Content blocks that are essentially similar or identical on multiple web sites are referred to as duplicate content.
Let’s examine each of its forms in more detail:
Exact duplicates
These are the most basic forms of duplicate content, in which entire sections or pages are copied without any changes. Search engines, such as Google, strive to provide consumers with distinct and diverse content; hence, encountering duplicate content can lead to confusion and dilute search results.
Near duplicates
Unlike exact duplicates, near duplicates feature minor variations in content, such as synonyms, rearranged sentences, or slight rephrasing.
While these differences may seem insignificant, search engines still recognize them as duplicate content and may penalize websites for not providing original content.
Meta titles
Duplicate meta titles refer to instances where multiple pages on a website have identical title tags. Meta titles play a crucial role in SEO, as they provide a concise summary of the page’s content to search engines and users. Having duplicate meta titles can confuse search engines and hinder the visibility of your pages in search results.
Meta descriptions
Similar to meta titles, duplicate meta descriptions occur when multiple pages share identical or very similar descriptions.
Meta descriptions serve as snippets that describe the content of a webpage, influencing click-through rates from search engine results pages (SERPs). Duplicating meta descriptions can lead to lower click-through rates and reduced organic traffic.
H1 tags
The H1 tag is the most important heading tag on a webpage, signaling the main topic or theme of the content. When multiple pages within a website use the same H1 tag, it can create confusion for both search engines and users, as it becomes unclear which page is the primary source of information.
H2 tags
Similarly, duplicate H2 tags denote repeated subheadings across different pages. H2 tags help organize content and provide structure for readers and search engines. When used excessively or duplicated, H2 tags can disrupt the flow of information and impact the overall user experience.
H3 tags
H3 tags further categorize and subdivide content under H2 headings. While having multiple H3 tags within a page is common and encouraged, duplicating them across different pages can signal redundancy and lack of originality to search engines.
In short, duplicate content comes in various forms, ranging from exact replicas to subtle variations.
By identifying and addressing these instances, website owners can enhance their SEO efforts and provide users with valuable, unique content that stands out in the digital landscape.
Duplicate Content Example
Imagine you’re managing an e-commerce website selling handmade jewellery. Your product descriptions are meticulously crafted to highlight the uniqueness and quality of each item.
However, due to a technical glitch or oversight, you discover that the same product description has been unintentionally copied and pasted across multiple product pages.
Upon closer inspection, you notice that not only are the descriptions identical, but the meta titles and meta descriptions for these pages are also the same.
This creates a perplexing situation where search engines struggle to discern which page to prioritize in search results, ultimately diminishing the visibility of your products.
Furthermore, within the product pages themselves, the H1 tags, H2 tags, and even H3 tags are duplicated, leading to a disorganized and repetitive user experience.
Customers may become frustrated trying to navigate through redundant information, resulting in higher bounce rates and decreased conversions.
In this example, the presence of duplicate content extends beyond mere textual repetition—it encompasses various elements such as meta data and HTML structure.
Addressing these instances promptly and implementing preventive measures can safeguard your website’s integrity and bolster its SEO performance.
By rectifying duplicate content issues and ensuring each page offers distinct and valuable information, you not only improve your website’s search engine rankings but also enhance the overall user experience, fostering trust and loyalty among your audience.
How to Check for Duplicate Content
1. Locate Duplicate Content
To embark on our quest, we need a trusty map and a keen eye. Here are four tried-and-tested methods to guide us:
STEP #1: Crawl Tool
Picture yourself equipped with a powerful torch, illuminating the darkest corners of your website with tools like Screaming Frog or Sitebulb. These crawl tools act as our trusty companions, revealing any duplicates lurking in the shadows.
STEP #2: Analytics Page Titles
Next, let’s delve into the heart of our website’s analytics. Keep a close watch on the titles of our pages – oftentimes, duplicates reveal themselves through identical or strikingly similar titles, like twin stars in the night sky.
STEP #3: Google Search Console Performance
Now, let’s tap into the wisdom of the oracle itself – Google Search Console. Here, in the Performance section, lies a wealth of insights waiting to be uncovered. Pay attention to any abnormalities that might hint at duplicate content lurking beneath the surface.
STEP #4: Google Search Console, Page Indexing Report
Lastly, let’s consult the ancient scrolls of the Page Indexing Report in Google Search Console. This repository of knowledge unveils which pages search engines have deemed worthy of indexing, guiding us in our quest to uncover duplicates.
2: Review Duplicated Content
Armed with our findings, it’s time to assess the situation. Let’s ask ourselves these important questions:
Do the pages have identical or nearly identical content?
With a discerning eye, let’s scrutinize the content of our suspected duplicates. Are they mirror images or simply close relatives? Understanding the degree of similarity is key to devising our strategy.
Do the pages serve a similar purpose?
Let’s ponder the purpose and intent behind each page. Are they offering distinct value to our audience, or do they tread on each other’s toes? Clarity on this front will shape our next steps.
How are visitors interacting with the duplicated pages?
Let’s delve back into our analytics, this time to observe the behaviour of our visitors. Are they engaging equally with both versions of the content, or does one overshadow the other? Understanding their interactions guides our decisions.
3. How to Find Duplicate Content on Your Website
Embarking on our journey begins with a keen eye and a strategic approach. To navigate the labyrinth of our website and uncover duplicates, consider these steps:
Step 1: Conduct a Thorough Website Audit
Begin by conducting a comprehensive audit of your website’s content. This involves scrutinizing every nook and cranny, from individual pages to metadata, to identify any instances of duplication.
Step 2: Utilize Specialized Tools
Equip yourself with specialized tools designed to detect duplicate content. Crawling software such as Screaming Frog or Site bulb can systematically analyse your website, flagging any duplicate pages or content blocks for your attention.
Step 3: Analyse Website Analytics
Dive into your website analytics to gain deeper insights into user behavior and page performance. Look for patterns that may indicate duplicate content, such as pages with unusually high bounce rates or low engagement metrics.
Step 4: Review Search Engine Indexing
Examine how search engines index your website’s pages. Tools like Google Search Console can provide invaluable data on indexed pages, helping you identify any duplicates that may have slipped through the cracks.
4: Using Google to Check for Duplicate Content
Harnessing the power of Google’s vast index, you can further refine your search for duplicate content. Here’s how:
Step 1: Perform Strategic Searches
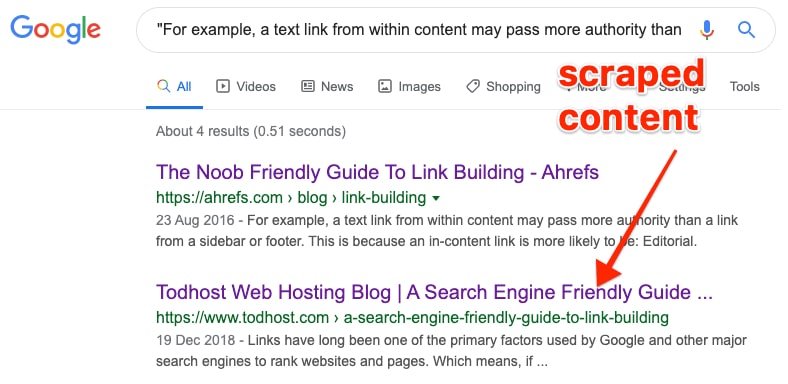
Craft targeted search queries using specific phrases or snippets of text from your website. By enclosing these phrases in quotation marks, you can instruct Google to search for exact matches, revealing any duplicate content that may exist.
Step 2: Explore Google’s Search Operators
Familiarize yourself with Google’s array of search operators, such as “site:” or “intitle:”. These operators allow you to narrow your search to specific sections of your website or to uncover duplicate content across multiple domains.
Step 3: Scrutinize Search Engine Results
Thoroughly examine the search engine results pages (SERPs) for your targeted queries. Look for any duplicate listings or snippets that may indicate identical or closely related content across different pages.
Armed with these strategies and insights, you’re well-equipped to embark on your quest to identify duplicate content and enhance your website’s SEO performance. So, saddle up and let the adventure begin!
Risks and Consequences
SEO Implications
In the realm of search engine optimization (SEO), originality reigns supreme. Duplicate content sends confusing signals to search engines, diluting the relevance and authority of your website.
As a result, your rankings may suffer, relegating your carefully crafted content to the murky depths of search engine obscurity.
The repercussions extend beyond visibility, impacting organic traffic, user engagement, and ultimately, the success of your online presence.
Legal Ramifications
Beyond the realm of algorithms and rankings lies a legal minefield awaiting those who disregard copyright and intellectual property laws.
Plagiarism and unauthorized duplication of content can lead to legal disputes, tarnishing your reputation and exposing your business to costly litigation.
Whether unintentional or deliberate, the consequences of infringing on the rights of content creators can be severe, jeopardizing the integrity and credibility of your brand.
In essence, the risks and consequences of duplicate content are manifold, encompassing both the digital realm of SEO and the legal landscape of intellectual property rights.
By prioritizing originality and vigilantly guarding against duplication, you not only safeguard your website’s SEO performance but also uphold ethical standards and legal compliance, ensuring a sustainable and reputable online presence.
How Search Engines Handle Duplicate Content
In the intricate world of search engine optimization (SEO), understanding how search engines handle duplicate content is paramount. Let’s delve into the mechanisms at play:
Algorithms and Filters
Search engines employ sophisticated algorithms and filters to identify and address duplicate content across the web. These algorithms are designed to analyse the similarity between web pages, identifying instances of duplication and determining which version to prioritize in search results.
Filters are then applied to ensure that users are presented with the most relevant and authoritative content, while minimizing the visibility of duplicates. While the specifics of these algorithms remain closely guarded secrets, search engines continuously refine their methodologies to provide users with the best possible search experience.
Impact on Rankings
The presence of duplicate content can have significant implications for a website’s rankings in search engine results pages (SERPs). When search engines encounter multiple versions of the same content, they must decide which page to display to users—a process known as content filtering.
In some cases, search engines may choose to penalize websites with duplicate content by lowering their rankings or excluding them from search results altogether. This can have a detrimental effect on organic traffic, visibility, and ultimately, the success of a website’s SEO efforts.
By addressing duplicate content issues proactively and ensuring that each page offers unique and valuable content, website owners can mitigate the negative impact on their rankings and enhance their overall SEO performance.
Understanding how search engines handle duplicate content is essential for optimizing your website’s visibility and maintaining compliance with search engine guidelines. By adhering to best practices and prioritizing originality, you can ensure that your content stands out in the digital landscape and resonates with both users and search engines alike.
Manual vs Automated Checks
In the dynamic realm of content management, the choice between manual and automated checks for identifying duplicate content can be a pivotal decision with far-reaching implications. Let’s explore the nuances of each approach:
Pros and Cons
Manual checks offer a hands-on, meticulous approach to content evaluation. With a human touch, content creators can scrutinize each page with precision, identifying subtle nuances and context that automated tools may overlook.
This method fosters a deeper understanding of the content landscape and allows for tailored solutions to unique challenges. However, manual checks are time-consuming and labour-intensive, requiring significant resources and attention to detail.
On the other hand, automated checks leverage the power of technology to streamline the detection process. With the click of a button, sophisticated algorithms can scan vast quantities of content, flagging potential duplicates with speed and efficiency.
This approach saves time and resources, allowing website owners to identify and address duplicate content more quickly. However, automated checks may lack the nuance and context provided by human oversight, leading to false positives or missed opportunities for optimization.
Recommended Approaches
Balancing the strengths and weaknesses of manual and automated checks is essential for effective duplicate content management. A hybrid approach that combines the precision of manual checks with the efficiency of automated tools offers the best of both worlds.
Start by conducting periodic manual audits to gain a comprehensive understanding of your content landscape and identify any potential issues. Then, supplement these efforts with automated tools to streamline the ongoing monitoring process and catch duplicates as they arise.
Another recommended approach is to prioritize manual checks for high-value or sensitive content, where accuracy and context are paramount. For larger websites with extensive content libraries, automated tools can help scale duplicate content detection efforts and ensure thorough coverage across all pages.
Ultimately, the key to successful duplicate content management lies in striking the right balance between manual and automated checks. By leveraging the strengths of each approach and tailoring your strategy to your specific needs, you can effectively identify and address duplicate content, improving your website’s SEO performance and enhancing the overall user experience.
Utilizing Search Operators
In the realm of duplicate content detection, mastering the art of utilizing search operators is akin to wielding a powerful tool in your arsenal. Let’s delve into two essential components of this strategy:
A. Leveraging Google Search
Google Search, with its vast index and sophisticated algorithms, offers a treasure trove of insights for identifying duplicate content.
By mastering basic search operators such as “site:” and “intitle:”, website owners can narrow their searches to specific domains or page titles, uncovering duplicate content hidden within their own website or across the web.
This method provides a quick and efficient way to pinpoint instances of duplication, allowing for targeted action to rectify the issue.
Additionally, Google’s search suggestions and auto-complete feature can offer valuable clues to potential duplicates, guiding website owners in their quest for originality.
B. Advanced Search Techniques
For those seeking to delve deeper into the intricacies of duplicate content detection, advanced search techniques offer a wealth of opportunities.
Experimenting with modifiers such as “filetype:” or “related:” can reveal additional layers of information, allowing website owners to explore alternative methods of identifying duplicates.
Additionally, leveraging Google’s advanced search operators such as “AROUND ()” or “AND/OR” can refine search queries to uncover more nuanced instances of duplication.
By combining these advanced techniques with strategic keyword selection and Boolean logic, website owners can unlock new insights and uncover hidden duplicates with precision.
By mastering the art of utilizing search operators and embracing advanced search techniques, website owners can elevate their duplicate content detection efforts to new heights.
With Google Search as their ally, armed with a comprehensive understanding of search operators and advanced techniques, website owners can navigate the digital landscape with confidence, ensuring their content remains original and impactful in the eyes of both users and search engines alike.
Common Causes of Duplicate Content
In the intricate ecosystem of online content, understanding the common causes of duplicate content is paramount for maintaining a strong SEO foundation. Let’s delve into the dual realms of internal and external factors contributing to this phenomenon:
Internal Factors
Within the confines of your own website, several internal factors can inadvertently give rise to duplicate content. For instance, the use of session IDs or tracking parameters in URLs can generate multiple versions of the same page, leading to confusion for search engines and users alike.
Similarly, content management systems (CMS) may produce duplicate pages through pagination, category archives, or tag archives, further complicating matters.
Additionally, inconsistent URL structures or canonicalization issues can exacerbate the problem, creating a tangled web of duplicate content that undermines your SEO efforts.
By addressing these internal factors head-on and implementing strategies to streamline content creation and management processes, website owners can mitigate the risk of duplicate content and enhance their online visibility.
External Factors
Beyond the confines of your own website, external factors can also contribute to the proliferation of duplicate content.
Content scraping, where unscrupulous individuals copy and republish your content without permission, is a prevalent issue that can lead to widespread duplication across the web.
Similarly, syndication agreements or content licensing arrangements may inadvertently result in duplicate content appearing on multiple platforms. Moreover, the proliferation of user-generated content, such as product descriptions or reviews, can also contribute to duplicate content issues if not managed effectively.
By vigilantly monitoring for instances of content scraping, negotiating syndication agreements carefully, and implementing robust content moderation practices, website owners can safeguard against external factors that contribute to duplicate content and preserve the integrity of their online presence.
By understanding the common causes of duplicate content and implementing proactive measures to address both internal and external factors, website owners can mitigate the risks and consequences associated with duplication and improve their SEO performance in the process.
Strategies for Preventing Duplicate Content
In the dynamic landscape of digital content, adopting proactive strategies for preventing duplicate content is crucial for maintaining a strong SEO foundation. Let’s explore two key approaches.
Content Creation Best Practices
At the heart of preventing duplicate content lies the adoption of robust content creation best practices. By prioritizing originality and relevance in content creation, website owners can minimize the risk of duplication from the outset.
This involves conducting thorough research to ensure that topics and themes are unique, and content is tailored to meet the needs and interests of the target audience.
Additionally, incorporating diverse formats such as videos, infographics, or podcasts can add value and differentiation to your content, reducing the likelihood of duplication.
Furthermore, implementing a clear editorial workflow and style guide can help maintain consistency and coherence across all content assets, mitigating the risk of unintentional duplication.
By fostering a culture of creativity and innovation in content creation, website owners can effectively prevent duplicate content and enhance the overall quality of their online presence.
URL Canonicalization
In addition to content creation best practices, URL canonicalization plays a pivotal role in preventing duplicate content. By establishing a canonical URL for each piece of content, website owners can consolidate multiple versions of the same page into a single authoritative source.
This involves selecting a preferred URL format and setting up canonical tags to instruct search engines on which version of the page to index and rank.
Additionally, implementing 301 redirects for duplicate or alternative URLs can further consolidate link equity and ensure a seamless user experience.
By adopting URL canonicalization best practices, website owners can effectively manage duplicate content issues arising from URL variations, parameterized URLs, or session IDs, thereby enhancing their website’s SEO performance and visibility.
By embracing content creation best practices and implementing URL canonicalization strategies, website owners can proactively prevent duplicate content and safeguard their SEO efforts.
Through a combination of creativity, diligence, and technical expertise, website owners can elevate their online presence and deliver valuable, original content that resonates with both users and search engines alike.
Handling Duplicate Content Issues
In the intricate dance of website management, navigating duplicate content issues requires a strategic approach grounded in both technical expertise and a human touch. Let’s explore two key strategies for handling duplicate content:
Redirects and Canonical Tag
Redirects and canonical tags serve as the guardians of content integrity in the digital realm, guiding search engines and users to the preferred version of a page.
Redirects, such as 301 redirects, seamlessly redirect traffic from duplicate or alternative URLs to the canonical URL, consolidating link equity and preserving the authority of the original content.
Similarly, canonical tags communicate to search engines the canonical URL of a page, ensuring that credit is attributed to the preferred version in search engine rankings.
By implementing redirects and canonical tags strategically, website owners can effectively manage duplicate content issues, enhance their website’s SEO performance, and deliver a seamless user experience.
Content Removal Strategies
In some cases, content removal may be necessary to address duplicate content issues effectively. Whether due to content duplication across multiple pages or the presence of outdated or irrelevant content, removal strategies can help streamline a website’s content landscape and mitigate the risks associated with duplication.
This may involve consolidating similar pages into a single authoritative source, pruning redundant or low-quality content, or removing outdated information altogether.
However, it’s essential to approach content removal with caution, ensuring that valuable content is preserved and redirected appropriately to maintain a positive user experience and prevent potential SEO implications.
By leveraging redirects and canonical tags alongside strategic content removal strategies, website owners can effectively handle duplicate content issues and optimize their website’s SEO performance.
With a balanced approach that prioritizes both technical solutions and user-centric considerations, website owners can navigate the complexities of duplicate content management with confidence, ensuring a seamless online experience for users and search engines alike.
Tools and Resources Check for Duplicate Content
In the labyrinth of digital content, identifying and rectifying duplicate content is paramount for maintaining a strong SEO foundation. Fortunately, there’s a myriad of tools and resources available to assist website owners in this endeavor. Let’s explore some of the top options:
Free Tools to Check for Duplicate Content
When it comes to cost-effective solutions, several free tools stand out for their effectiveness in detecting duplicate content:
- Copyscape
Copyscape has long been a trusted companion for website owners, offering a straightforward platform to scan websites and identify instances of duplication.
- Plagspotter
Plagspotter is another valuable tool in the arsenal, meticulously scouring the web to pinpoint potential cases of plagiarism and duplication.
- Duplichecker
Duplichecker provides comprehensive duplicate content checking capabilities, allowing website owners to gain insights into their content landscape without breaking the bank.
- Siteliner
Siteliner offers a holistic approach, analyzing entire websites to uncover duplicate content and provide actionable recommendations for improvement.
- Smallseotools
Last but not least, Smallseotools provides a suite of SEO utilities, including a duplicate content checker, making it a popular choice among website owners looking to enhance their SEO performance without investing in premium tools.
Premium Tools to Check for Content
For those seeking advanced features and unparalleled accuracy, premium tools offer a range of options to check for duplicate content:
- Grammarly
Grammarly, renowned for its grammar and spelling checking capabilities, also boasts a powerful plagiarism checker feature. This ensures that content remains original and authentic, providing peace of mind to website owners.
- Plagium
Plagium steps up with its robust platform, enabling users to detect plagiarism and duplicate content across various sources with precision and efficiency.
- Plagiarismcheck.org
Similarly, Plagiarismcheck.org delivers comprehensive plagiarism detection tools, including a duplicate content checker, to safeguard content integrity and maintain SEO performance at the highest level.
By leveraging both free and premium tools, website owners can effectively detect and address duplicate content issues, thereby enhancing their SEO performance and ensuring a seamless user experience.
Whether opting for the accessibility of free tools or the advanced features of premium solutions, investing in the right tools is essential for maintaining originality and driving success in the competitive digital landscape.
How To Fix Duplicate Content
In the pursuit of maintaining a strong SEO presence, addressing duplicate content issues is paramount. Let’s delve into effective strategies to tackle this challenge head-on: Duplicate content can undermine the visibility and credibility of your website, but there are actionable steps you can take to remedy the situation:
Title Tag Changes
Ensuring that each page on your website has a unique and descriptive title tag is crucial for distinguishing between similar content. By crafting compelling and keyword-rich title tags, you can enhance the relevance and clarity of your pages, making it easier for search engines to index and rank them appropriately.
Implementing Canonical URLs
Canonicalization is a powerful tool for consolidating duplicate content and signalling to search engines which version of a page is the preferred one. Here’s how you can implement canonical URLs effectively:
a) Select Canonical Page:
Identify the primary version of the content that you want search engines to index and rank.
b) Add a Canonical Tag:
Insert a canonical tag in the HTML code of duplicate pages, specifying the canonical URL of the primary version.
c) Supporting The Canonical:
Ensure that internal links and sitemaps point to the canonical URL, reinforcing its authority and signalling its importance to search engines.
Consolidating or Removing Content & Redirects
In cases where duplicate content exists across multiple pages, consider consolidating similar content into a single authoritative source.
Alternatively, if certain pages are redundant or outdated, consider removing them altogether. Implementing 301 redirects from removed pages to relevant, existing content can preserve link equity and maintain a seamless user experience.
Fixing Underlying Technical or Structural Issues
Address any underlying technical or structural issues that may be contributing to duplicate content. This could include resolving URL parameterization issues, optimizing pagination strategies, or improving content management processes to prevent inadvertent duplication in the future.
By taking proactive steps to fix duplicate content issues, you can strengthen your website’s SEO performance and ensure that your content resonates with both users and search engines alike.
With a combination of strategic adjustments and diligent maintenance, you can uphold the integrity and relevance of your content, ultimately driving greater visibility and engagement across the digital landscape.
By following all these methods you can fix the duplicity of content from your website or you can consult any expert service provider.
Conclusion
As we conclude our exploration into identifying and combating duplicate content to bolster SEO efforts, it’s essential to reflect on the key takeaways and recap the strategies and tools discussed.
Awareness is Key: Understanding the implications of duplicate content is the first step toward addressing it effectively.
Proactive Measures: Implementing proactive strategies such as content analysis, URL canonicalization, and regular site audits can help mitigate the risk of duplicate content.
Utilize Tools: Leveraging a combination of free and premium tools, such as Copyscape, Grammarly, and Plagium, can streamline the detection and resolution process.
Technical Optimization: Addressing underlying technical or structural issues, such as URL parameterization and pagination, is essential for long-term content integrity.
Consistent Monitoring: Regularly monitoring and maintaining your website’s content landscape is crucial to staying ahead of potential duplication issues.
Content Analysis: Conduct thorough content analysis using tools like Copyscape and Siteliner to identify instances of duplicate content.
URL Canonicalization: Implement canonical URLs and 301 redirects to consolidate duplicate content and signal search engines to the preferred version.
Regular Audits: Perform regular audits of your website’s content to identify and address any emerging duplication issues.
Utilize Tools: Take advantage of both free and premium tools, such as Grammarly and Plagium, to streamline the duplicate content detection process.
By incorporating these key takeaways and strategies into your SEO approach, you can effectively identify and mitigate duplicate content issues, ultimately enhancing the visibility and credibility of your website.
Remember, staying vigilant and proactive in managing duplicate content is essential for maintaining a strong and authoritative online presence.
Frequently Asked Questions
What is duplicate content?
Duplicate content refers to blocks of content that appear in multiple locations on the internet, whether within a single website or across different domains. It can take various forms, including identical text, similar variations, or near duplicates.
How does duplicate content affect SEO?
Duplicate content can have detrimental effects on SEO by diluting the relevance and authority of individual pages. Search engines may struggle to determine the most relevant version of content, leading to lower rankings, reduced organic traffic, and potential penalties.
How can I check for duplicate content on my website?
You can check for duplicate content using a variety of methods, including manual inspection, content analysis tools, and specialized SEO software. These tools can help identify instances of duplication and provide recommendations for remediation.
What should I do if I find duplicate content?
If you discover duplicate content on your website, it's essential to take action promptly. Depending on the situation, you may choose to consolidate similar content, implement canonical tags, or remove redundant pages altogether to avoid SEO implications.
How often should I check for duplicate content?
Regular monitoring and auditing of your website's content landscape are crucial to identifying and addressing duplicate content issues. Aim to conduct duplicate content checks periodically, especially after making significant content updates or changes to your website structure.
Are there any tools to automate duplicate content checks?
Yes, several tools are available to automate duplicate content checks, ranging from free online utilities to premium SEO software. These tools can streamline the detection process and provide actionable insights to improve content integrity.
Can duplicate content issues be completely avoided?
While it may be challenging to completely eliminate duplicate content issues, proactive measures such as implementing canonical tags, optimizing URL structures, and enforcing content guidelines can significantly mitigate the risk.
Is duplicate content always intentional?
Not necessarily. Duplicate content can arise unintentionally due to various factors, including content syndication, URL parameters, and technical issues. However, addressing duplicate content promptly is crucial to maintaining SEO integrity.
How does duplicate content affect user experience?
Duplicate content can confuse and frustrate users by presenting redundant or conflicting information. This can undermine user trust and satisfaction, leading to a negative impact on overall user experience.
Should I be concerned about duplicate content from syndication or quoting sources?
While syndicating content or quoting sources is a common practice, it's essential to ensure that proper attribution and canonicalization are in place to avoid potential duplicate content issues. By following best practices and providing unique value to users, you can mitigate the risks associated with syndicated or quoted content.